- 06-41226543
- info@connectyourworld.nl


Last Updated on 23 juni 2025 by connectyourworld
Heeft u wel eens van de sitemap robots txt gehoord? Hoewel u een website kunt maken volgens, die goed is geoptimaliseerd voor SEO optimalisatie, moeten crawlers van zoekmachines zoals Google en Bing uw website nog steeds vinden en crawlen. Eigenlijk heeft u best wel een beetje controle over hoe web crawlers uw website indexeren met sitemap robots.txt. Dit kan zelfs per pagina worden aangepakt.
Estimated reading time: 13 minuten
In deze blog leert u:
Als u inspraak wilt hebben in wat SEO robots op uw website doorkammen, heeft u hiervoor een robots.txt-bestand nodig. Hoewel het niet per se het laatste woord heeft over hoe Google uw website behandelt, kan het een krachtig effect hebben op uw SEO resultaten. Door u inspraak te geven in hoe Google uw site bekijkt, kunt u ook hun oordeel beïnvloeden. Dus, als u uw crawlfrequentie en zoekprestaties op Google wilt verbeteren, hoe kunt u dan een robots.txt voor SEO maken?
We gaan terug naar het begin van robots.txt-bestanden om het op te splitsen:
Laten we beginnen door te onderzoeken wat een robots.txt-bestand is.
Toen het internet nog jong was en vol potentie zat, bedachten web ontwikkelaars een manier om nieuwe pagina’s op internet te crawlen en te indexeren. Deze tools werden crawlers, spiders of robots genoemd. U heeft ze waarschijnlijk allemaal door elkaar horen gebruiken.
Zo nu en dan dwaalden deze robots af van waar ze hoorden te zijn. Ze begonnen namelijk met het crawlen en indexeren van websites, die niet bedoeld waren om geïndexeerd te worden. Er moest een oplossing komen. De maker van Aliweb, ‘s werelds eerste zoekmachine, adviseerde een “roadmap”-oplossing die de robots zou helpen op koers te blijven. In juni 1994 werd dit protocol gerealiseerd. Hoe ziet dit protocol eruit, wanneer het wordt uitgevoerd?

Het protocol stelt de richtlijnen vast die alle bots, inclusief die van Google, moeten volgen. Sommige robots met een donkere hoed, zoals spyware of malware, werken echter buiten deze regels. Wilt u zelf zien hoe het is? Typ gewoon de URL van een website, gevolgd door “/robots.txt” aan het einde.

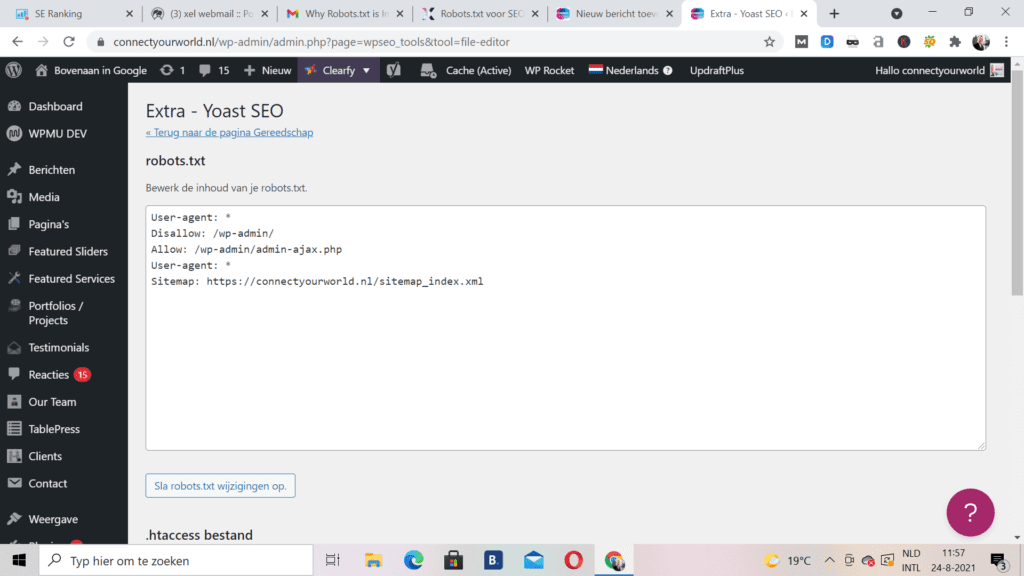
U vindt uw sitemap robots txt bestand in de hoofdmap van uw site. Om toegang te krijgen, opent u uw FTP en zoekt u vervolgens in uw public html-sitemap. Er zijn niet veel van deze bestanden, dus ze zullen niet zo groot zijn. Verwacht maximaal een paar honderd bytes te zien. Zodra u het bestand hebt geopend in uw tekst editor, ziet u wat informatie over een sitemap en de termen ‘User-Agent’, ‘toestaan’ en ‘niet toestaan’. U kunt ook gewoon /robots.txt toevoegen aan het einde van de meeste URL’s om het te vinden:
Als u er zelf een moet maken, weet dan dat Robots.txt een eenvoudig tekstbestand is dat eenvoudig genoeg is voor een echte beginner om te maken. Zorg ervoor, dat u een eenvoudige tekst editor hebt en open vervolgens een leeg blad dat je opslaat als “robots.txt”. Log vervolgens in en zoek de map public_html zoals hierboven vermeld. Met het bestand geopend en de map omhoog getrokken, sleept u het bestand naar de map. Stel nu de juiste machtigingen voor het bestand in. U wilt dat het zo wordt ingesteld dat u, als eigenaar, de enige partij bent met toestemming om dat bestand te lezen, schrijven en bewerken. U zou een machtigingscode “0644” moeten zien. Als u die code niet ziet, klikt u op het bestand en selecteert u vervolgens ‘bestandsmachtiging’. Helemaal klaar!
Als u naar het bovenstaande robots.txt-voorbeeld kijkt, ziet u waarschijnlijk een onbekende syntaxis. Dus wat betekenen deze woorden? Laten we het uitzoeken. De bestanden bestaan uit meerdere secties, elk een “richtlijn”. Elke instructie begint met een gespecificeerde user-agent, die onder de naam staat van de specifieke crawlbot waarop de code is gericht.
U heeft hier twee opties:
Wanneer een crawler naar een site wordt gestuurd, wordt deze aangetrokken door het gedeelte, dat erover spreekt. Elke zoekmachine zal SEO site robot.txt-bestanden een beetje anders behandelen. U kunt eenvoudig onderzoek doen om meer te weten te komen over hoe Google of Bing in het bijzonder met dingen omgaat.
Zie het gedeelte “user-agent”? Dit onderscheidt een bot van de rest, in wezen door hem bij naam te noemen. Als het uw doel is om een van de crawlers van Google te vertellen, wat ze op uw site moeten doen, begin dan met ‘User-agent: Googlebot’. Hoe specifieker u echter kunt worden, hoe beter. Het is gebruikelijk om meer dan één richtlijn te hebben, dus noem elke bot indien nodig bij naam.
Pro-tip: de meeste zoekmachines gebruiken meer dan één bot. Een beetje onderzoek zal u de meest voorkomende bots vertellen waarop u zich kunt richten.
Dit gedeelte wordt momenteel alleen ondersteund door Yandex, hoewel u mogelijk enkele beweringen ziet dat Google dit ondersteunt. Met deze richtlijn heeft u de bevoegdheid om te bepalen of u de www. voor uw site-URL door zoiets als dit te zeggen:
Host:voorbeeld.com
Omdat we alleen kunnen bevestigen dat Yandex dit ondersteunt, is het niet aan te raden om er te veel op te vertrouwen.
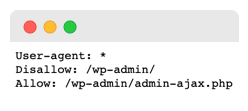
De tweede regel binnen een sectie is Disallow. Met deze tool kunt u aangeven welke delen van uw websites niet door bots mogen worden gecrawld. Als u de disallow leeg laat, vertelt het de bots in wezen dat het gratis is en dat ze kunnen kruipen wanneer ze willen.
De sitemap-richtlijn helpt u zoekmachines te vertellen waar ze uw XML-sitemap kunnen vinden, een digitale kaart die zoekmachines kan helpen belangrijke pagina’s op uw site te vinden en te leren hoe vaak ze worden bijgewerkt.
U zult merken, dat zoekmachines zoals Bing en Google een beetje trigger happy kunnen worden tijdens het crawlen. U kunt ze echter een tijdje op afstand houden met een crawl-delay-initiatief. Wanneer u een regel toepast met de tekst ‘Crawl-delay:10’, vertelt u de bots tien seconden te wachten voordat ze de site crawlen of tien seconden tussen crawls.
Nu we de basisprincipes van robots.txt-bestanden hebben behandeld en een aantal richtlijngebruiken hebben besproken, is het tijd om uw bestand samen te stellen. Hoewel een robots.txt bestand geen verplicht onderdeel is van een succesvolle website, zijn er toch veel belangrijke voordelen waarvan u op de hoogte moet zijn:
U wilt natuurlijk, dat zoekmachines zich een weg banen door de meest kritische pagina’s op uw website. Als u de bots beperkt tot specifieke pagina’s, heeft u betere controle over welke pagina’s vervolgens voor zoekers op Google worden geplaatst. Zorg er wel voor, dat u een crawler nooit helemaal blokkeert om bepaalde pagina’s te zien – u kunt er boetes voor krijgen.
Als u niet wilt dat een crawler een pagina opent, gebruikt u meestal een disallow- of noindex-instructie. In 2019 kondigde Google echter aan dat ze het niet langer ondersteunen, samen met een paar andere regels. Voor degenen die de no index-richtlijn toch wilden toepassen, moesten we creatief zijn. Er zijn in plaats daarvan een paar opties om uit te kiezen:
Dus, wat is beter? Noindex of de disallow-regel? Laten we erin duiken. Aangezien Google noindex officieel niet langer ondersteunt, moet u vertrouwen op de hierboven genoemde alternatieven of op de beproefde regel voor niet toestaan. Houd er rekening mee, dat de disallow-regel niet zo effectief zal zijn als de standaard noindex-tag zou zijn. Hoewel het de bots blokkeert om die pagina te crawlen, kunnen ze nog steeds informatie van andere pagina’s verzamelen, evenals zowel interne als externe links, wat ertoe kan leiden dat die pagina in SERP’s wordt weergegeven.
Geef ons uw site (of klanten) en we analyseren de SEO elementen van de site (on-page, URL-gelijkheid, concurrenten, enz.), en organiseren deze gegevens vervolgens in een bruikbare SEO audit.
We hebben het nu gehad over wat een robots.txt-bestand is, hoe u er een kunt vinden of maken, en de verschillende manieren om het te gebruiken. Maar we hebben het nog niet gehad over de veelvoorkomende fouten, die te veel mensen maken bij het gebruik van robots.txt-bestanden. Wanneer het niet correct wordt gebruikt, kunt u een SEO-ramp tegenkomen. Vermijd dit lot door deze veelvoorkomende fouten te vermijden:
U wilt geen goede content blokkeren, die nuttig zou kunnen zijn voor sitecrawlers en gebruikers die naar uw site zoeken via zoekmachines. Als u een no index-tag of robots.txt-bestand gebruikt om goede content te blokkeren, schaadt u uw eigen SEO resultaten. Als u achterblijvende resultaten opmerkt, controleer dan uw pagina’s grondig op disallow-regels of noindex-tags.
Als u de crawl-delay-richtlijn te vaak gebruikt, beperkt u het aantal pagina’s, dat de bots kunnen crawlen. Hoewel dit misschien geen probleem is voor grote sites, kunnen kleinere sites met beperkte content hun eigen kansen op het behalen van hoge SERP-ranglijsten schaden door deze tools te veel te gebruiken.
Als u wilt voorkomen dat bots de pagina rechtstreeks crawlen, kunt u dit het beste weigeren. Het zal echter niet altijd werken. Als de pagina extern is gelinkt, kan deze nog steeds doorstromen naar de pagina. Bovendien onderschrijven onwettige bots zoals malware deze regels niet, dus indexeren ze de content toch.
Het is belangrijk op te merken, dat sitemap robots.txt-bestanden hoofdlettergevoelig zijn. Een richtlijn maken en een hoofdletter gebruiken, werkt niet. Alles moet in kleine letters zijn als u wilt dat het effectief is.
Soms is duplicated content nodig en wilt u deze verbergen zodat deze niet wordt geïndexeerd. Maar andere keren weten Google-bots, wanneer u iets probeert te verbergen, dat niet verborgen zou moeten zijn. Een gebrek aan content kan soms de aandacht vestigen op iets vreemds. Als Google ziet, dat u de ranglijst probeert te manipuleren om meer verkeer te krijgen, kunnen ze u straffen. Maar u kunt dit omzeilen door duplicated content te herschrijven, een 301-omleiding toe te voegen of een Rel=”canonieke tag te gebruiken.
Nu u alles weet over robots.txt voor SEO, is het tijd om wat u heeft geleerd te gebruiken om een bestand te maken en het uit te testen. Het kan even duren voordat u het proces onder de knie hebt en ervoor zorgt dat u alles heeft ingesteld zoals u wilt, maar als u eenmaal alles heeft ingesteld, zult u het verschil zien. Dat is de kracht van sitemap robots txt bestanden.
Herman Geertsema is een ervaren SEO consultant en Content Marketing expert uit Den Haag. Tevens is Herman eigenaar van Connect your World, een SEO bureau in Den Haag.
Kies ook een SEO specialist uit om bovenaan Google te komen in de volgende regio´s:
Heeft u een vraag voor ons? Of wilt u ons als SEO specialist inhuren? Neem dan contact met ons op.
Herman Geertsema is een zeer ervaren freelance SEO specialist met meer dan 10 jaar ervaring. Daarnaast is hij al meer dan 20 jaar werkzaam als content marketeer. Om zich verder te specialiseren heeft hij een HBO opleiding Internetmanagement en Webdesign succesvol afgerond. In online projecten kan Herman ook de rol van projectmanager/scrummaster op zich nemen, aangezien hij Scrum gecertificeerd is. In 2018 kwam Herman zijn droom uit en startte hij zijn eigen SEO en Content Marketing bureau Connect your World in Den Haag. Inmiddels bestaat Connect your World ruim 5 jaar waarin hij (MKB) bedrijven helpt met het verbeteren van hun online zichtbaarheid om zo een hogere omzet en meer winst te behalen. Naast zijn uitgebreide kennis van On en Off Page SEO, Technische SEO, lokale SEO en het schrijven van webteksten is Herman ook een strategisch sparringpartner. Bij Connect your World houden wij van ambitieuze doelstellingen. Bent u na 6 maanden niet tevreden dan krijgt u 300 Euro retour. Connect your World houdt niet van het ‘uurtje factuurtje’ principe. Klanten noemen ons betrouwbaar en goed bereikbaar. We zijn inmiddels groot geworden door klein te blijven. Kijk voor meer informatie op https://connectyourworld.nl of neem contact op via info@connectyourworld.nl of tel 06-41226543 Met vriendelijke groet, Herman Geertsema, SEO specialist Den Haag
